
This is the group project of SDSC3006 – Fundamentals of Machine Learning I. I did the project in my year 3 2022/23 Semester A.
Presentation Slides:
Course Instructor: Prof. ZENG Li
Introduction
In this final project, me and my groupmates will be analyzing a dataset related to steel plates’ faults. The dataset consists of various features of steel plates, classified into seven different types of faults. The objective is to apply machine learning techniques to automatically recognize patterns and classify the steel plates based on their faults. This analysis aims to extend the learning from the course and provide insights into the practical application of machine learning in the field of material science.
Dataset Source
The dataset used in this project is the “Steel Plates Faults” dataset, which was donated to the UCI Machine Learning Repository on October 25, 2010. It contains data on steel plates’ faults, classified into seven different types. The dataset comprises 1941 instances, each with 27 features, including both integer and real-valued attributes. The features represent various characteristics of the steel plates, such as dimensions, area, perimeter, luminosity, and type of steel, among others.
The dataset can be accessed and downloaded from the UCI Machine Learning Repository through the following link: Steel Plates Faults – UCI Machine Learning Repository.
Additionally, the dataset can be easily imported into a Python environment using the ucimlrepo package, as demonstrated in the dataset description. This facilitates the process of loading the data for analysis and model building in the project.
Dataset Background
The “Steel Plates Faults” dataset is a multivariate dataset that falls under the subject area of physics and chemistry. It is primarily used for classification tasks in machine learning. The dataset does not contain any missing values, ensuring a smooth analysis process. The seven types of steel plates faults included in the dataset are Pastry, Z_Scratch, K_Scatch, Stains, Dirtiness, Bumps, and Other_Faults. Each instance in the dataset represents a steel plate with its corresponding features and fault type. This dataset provides a valuable resource for developing and testing machine learning models for automatic pattern recognition and classification in the context of material science.
Methodology

The analysis began with a pre-analysis stage, where the integrity of the dataset was confirmed; no missing or null values were found. This provided a solid foundation for a reliable analysis. A heatmap was generated to visualize the correlations among the variables, highlighting significant relationships, especially between luminosity-related features and the steel plates’ perimeter.


Following the preliminary examination, Principal Component Analysis (PCA) was employed to reduce the dataset’s dimensionality. This method transformed the dataset into a set of linearly uncorrelated variables, known as principal components (PCs). It was determined that ten PCs accounted for 90% of the variance in the dataset, thus providing a simplified yet comprehensive view of the data for further analysis.

Using the first ten PCs, a decision tree model was constructed using the ANOVA method to predict the types of faults in steel plates. The model was specifically applied to predict bumps as a type of fault. The decision tree provided a clear, visual representation of the classification process, delineating the path taken to reach a prediction based on the values of the PCs.
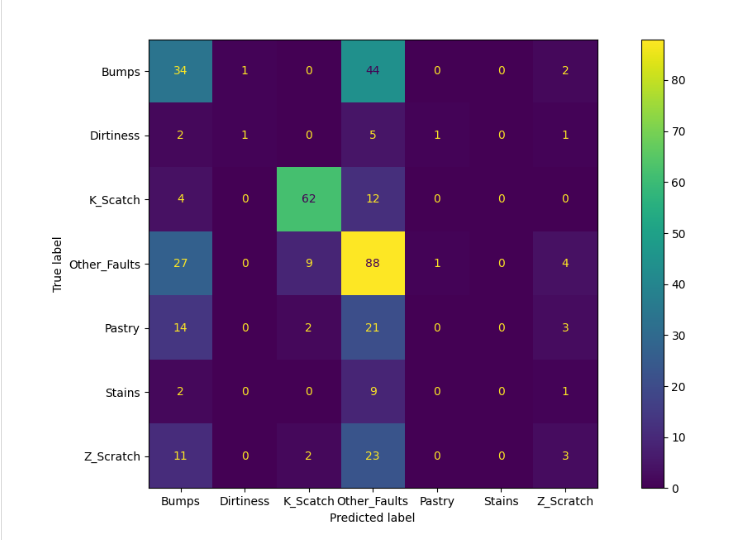

To assess the model’s performance, a confusion matrix was constructed for a K Nearest Neighbors classifier. This matrix served as an accuracy indicator, though it also revealed that surface defects were prone to misclassification.
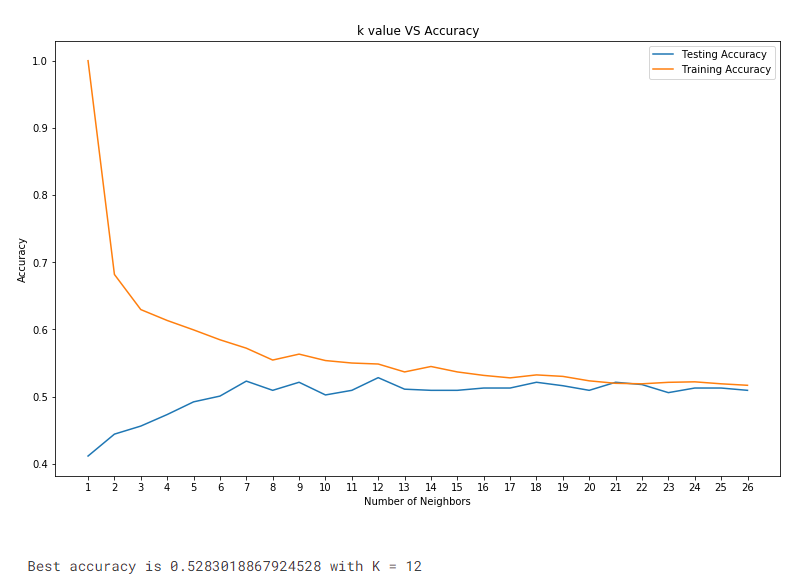
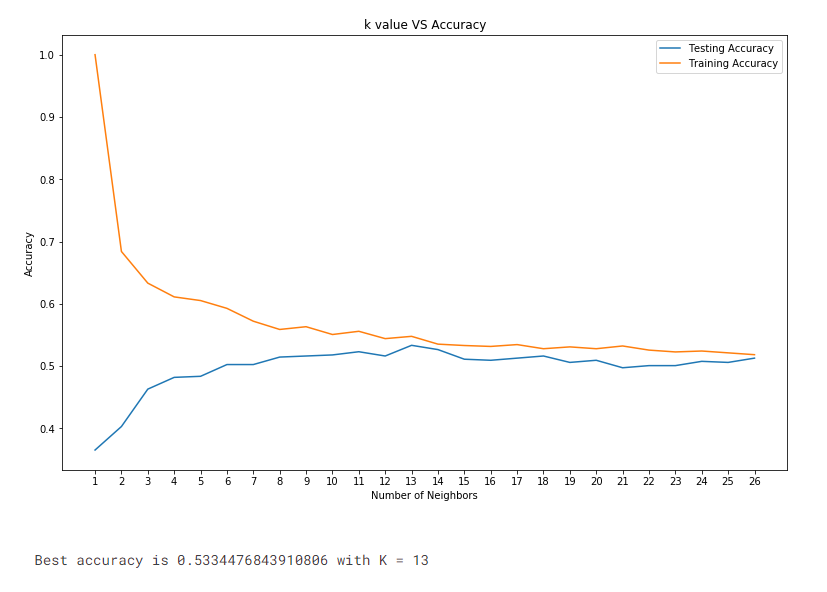
The K-value’s impact on the model’s accuracy was evaluated, revealing that a balance needed to be struck to avoid overfitting; the model’s complexity adversely affected its performance.
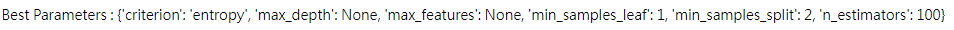
The Random Forest model was then introduced, employing the GridSearchCV function in Python to optimize the model’s parameters. The chosen metrics included the criterion of entropy, with one hundred trees, and no limit on the maximum depth or the number of features considered for the best split.
Findings
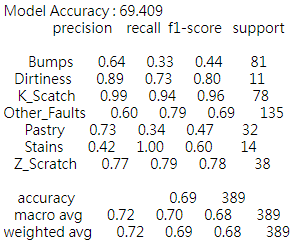
The Decision Tree and Random Forest models demonstrated varying degrees of success in classifying the types of steel plates faults. While the Random Forest model exhibited approximately 69% accuracy, it was noted that this came with a relatively high computational cost, affecting the model’s efficiency.
Precision-recall analysis within the Random Forest model indicated that it predicted K_Scatch and Dirtiness faults with the highest precision. Conversely, other fault types, such as Bumps and Stains, presented challenges for the model.
Conclusion
The analysis successfully leveraged techniques of machine learning to classify faults in steel plates. Despite the computational intensity, the Random Forest model proved to be a robust classifier, offering a balance between precision and recall, thus making it a reliable predictor for certain types of faults. The K Nearest Neighbors classifier, while simpler and faster, was less effective at distinguishing between the different fault categories. It was particularly challenged by overlapping fault characteristics that led to misclassifications.
Through the process of model selection and optimization, this project highlighted the importance of choosing the right model based on the specific characteristics of the dataset. The need to balance the model’s complexity with its predictive power was evident, particularly when dealing with a high-dimensional space and a multitude of classes, as in the case of the steel plates faults dataset.
First Decision Tree from the Random Forest:
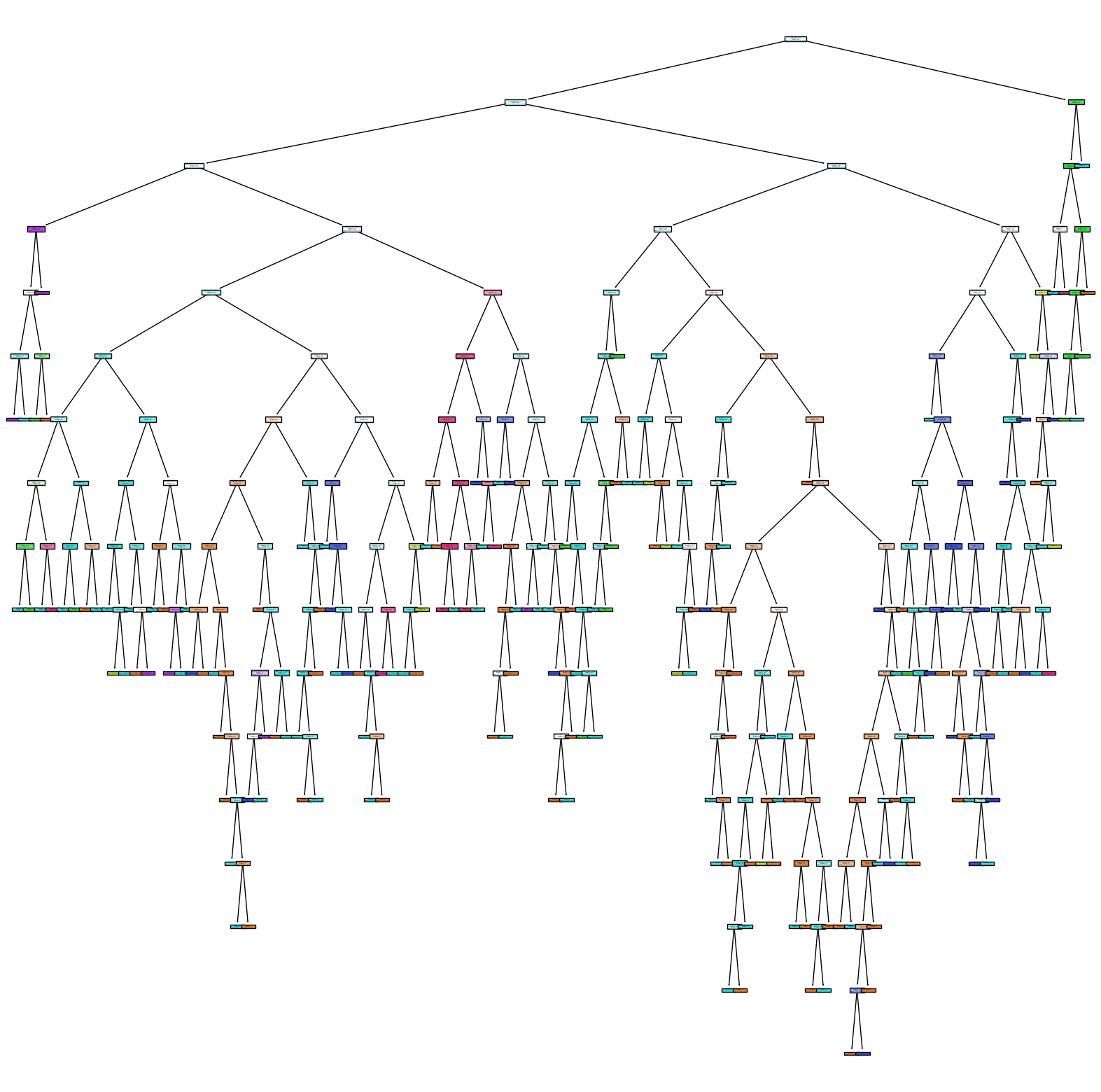
First Decision Tree with Max Depth=2:
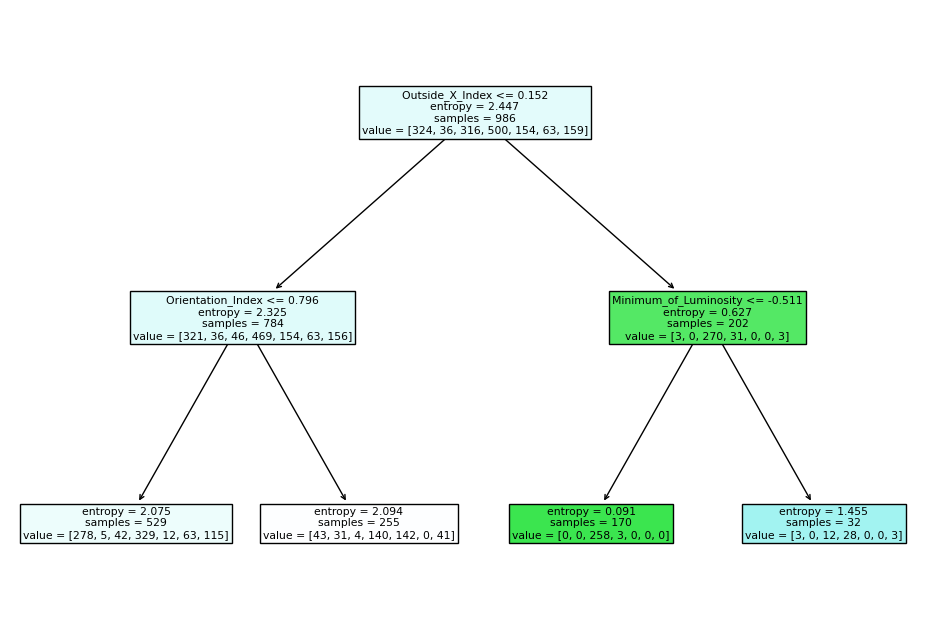
The final step was to refine the Decision Tree within the Random Forest, limiting its depth to enhance interpretability and prevent overfitting. The final Decision Tree model, with a maximum depth of two, provided a more interpretable and visually comprehensible model, though at the cost of detailed granularity.
In summary, this project not only solidified the theoretical knowledge gained from the class but also provided a practical application of machine learning techniques to a real-world problem. It underscored the potential of machine learning in industrial applications, particularly in automating the fault classification process in manufacturing environments, which can significantly enhance quality control measures.
The journey from pre-analysis to the conclusion has underscored the iterative nature of data science; through trial and error, refinement of techniques, and validation of results, we can draw meaningful insights from data.
Appendix
Our Code:
# Importing necessary libraries for data manipulation and visualization
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from subprocess import check_output
# Importing machine learning libraries and functions
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
df = pd.read_csv('faults.csv')
# Selecting the label columns (the first seven columns of the dataset)
label_columns = df.columns.values[:7]
# Separating the target variable which is the maximum fault type label for each instance
targets = (df.iloc[:, :7] == 1).idxmax(1)
# Preparing the dataset by dropping the label columns and adding a target column
dataset = df.drop(label_columns, axis=1)
dataset['target'] = targets
# Dropping additional columns that are not needed for the analysis
dataset = dataset.drop('TypeOfSteel_A400', axis=1)
dataset = dataset.drop('X_Minimum', axis=1)
dataset = dataset.drop('Y_Minimum', axis=1)
# Selecting features for the model (first 24 columns)
X = dataset.iloc[:, :24]
# Selecting the target column for the model
y = dataset.iloc[:, 24]
# Splitting the dataset into training and testing sets with a test size of 20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Instantiating the KNN classifier with 19 neighbors
knn = KNeighborsClassifier(n_neighbors=19)
# Fitting the model on the training data
knn.fit(X_train, y_train)
# Predicting on the test set and printing the accuracy
classifier = knn.fit(X_train, y_train)
print("KNN accuracy:", knn.score(X_test, y_test))
# Plotting the confusion matrix to visualize the performance of the classifier
plot_confusion_matrix(classifier, X_test, y_test, labels=None, sample_weight=None, normalize=None)
plt.show()
# This second part of the code is for finding the best number of neighbors
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# Preparing features and target variable again
X, y = df.loc[:, df.columns != 'class'], df.loc[:, 'class']
# Splitting the dataset into training and testing sets with a test size of 30% and shuffling
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 2, shuffle=True)
# Initializing lists to store accuracy for training and testing sets
train_accuracy = []
test_accuracy = []
# Trying different numbers of neighbors to find the best one
neig = np.arange(1, 27)
for i, k in enumerate(neig):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
# Storing the accuracy for the current number of neighbors
train_accuracy.append(knn.score(X_train, y_train))
test_accuracy.append(knn.score(X_test, y_test))
# Plotting the accuracy for different numbers of neighbors
plt.figure(figsize=(13, 8))
plt.plot(neig, test_accuracy, label = 'Testing Accuracy')
plt.plot(neig, train_accuracy, label = 'Training Accuracy')
plt.legend()
# Labeling the plot
plt.title('k value VS Accuracy')
plt.xlabel('Number of Neighbors')
plt.ylabel('Accuracy')
# Showing the plot
plt.show()
# Printing the best accuracy and corresponding k
print("Best accuracy is {} with k = {}".format(np.max(test_accuracy),1+test_accuracy.index(np.max(test_accuracy))))
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.preprocessing import StandardScaler
from sklearn import tree
%matplotlib inline
# Ignore warnings
import warnings
warnings.filterwarnings("ignore")
# Load dataset
df = pd.read_csv("faults.csv")
# Define conditions and choices for class labels
conditions = [
(df['Pastry'] == 1) & (df['Z_Scratch'] == 0) & (df['K_Scatch'] == 0) & (df['Stains'] == 0) & (df['Dirtiness'] == 0) & (df['Bumps'] == 0) & (df['Other_Faults'] == 0),
(df['Pastry'] == 0) & (df['Z_Scratch'] == 1) & (df['K_Scatch'] == 0) & (df['Stains'] == 0) & (df['Dirtiness'] == 0) & (df['Bumps'] == 0) & (df['Other_Faults'] == 0),
# Add other conditions here
]
choices = ['Pastry', 'Z_Scratch', 'K_Scatch', 'Stains', 'Dirtiness', 'Bumps', 'Other_Faults']
# Create a new column for class labels
df['class'] = np.select(conditions, choices)
# Drop unnecessary columns
df.drop(choices, inplace=True, axis=1)
# Define features and target variable
x = df.drop('class', axis=1)
y = df['class']
# Split data into training and test sets
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1, stratify=y)
# Standardize features
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# Function to evaluate and fit the model
def model_eval(model, param_grid, cv=5):
grid_search = GridSearchCV(model, param_grid, cv=cv)
grid_search.fit(x_train, y_train)
# Print best parameters
print("Best Parameters:", grid_search.best_params_)
# Make predictions
y_pred = grid_search.predict(x_test)
# Confusion matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
# Print model accuracy and classification report
print("Model Accuracy:", round(grid_search.score(x_test, y_test) * 100, 3))
print(classification_report(y_test, y_pred))
# Define the model and parameter grid
rf = RandomForestClassifier()
param_grid = {
'n_estimators': [50, 100, 200],
'criterion': ['gini', 'entropy'],
'min_samples_split': [2, 5, 10],
'max_depth': [None, 2],
'min_samples_leaf': [1, 5, 10],
'max_features': [None, 'auto', 'sqrt', 'log2']
}
# Evaluate the model
model_eval(rf, param_grid)
# Example of fitting a RandomForestClassifier with specific parameters
rf1 = RandomForestClassifier(n_estimators=50, min_samples_split=2, min_samples_leaf=1, max_features=None, max_depth=2, criterion='entropy')
rf1.fit(x_train, y_train)
# Print the maximum depth of the first tree
print("Maximum depth of the first tree:", rf1.estimators_[0].tree_.max_depth)
# Visualize one of the trees from the random forest
plt.rcParams.update({'figure.figsize': (12, 8)})
plt.rcParams.update({'font.size': 14})
_ = tree.plot_tree(rf1.estimators_[0], feature_names=df.columns[:-1], filled=True)
some of the pictures in your sdsc3006 project are broken. Please fix it?